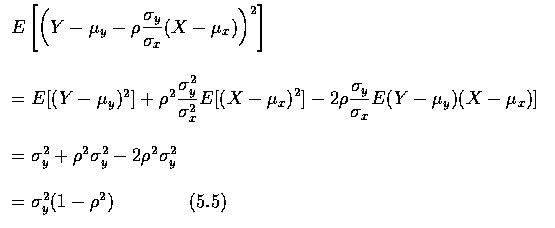![$\begin{array}{l}
E[(Y-(a+bX))^2] \\ \\
=E[Y^2-2aY-2bXY+a^2+2abX+b^2X^2] \\ \\
=E[Y^2]-2aE[Y]-2bE[XY]+a^2+2abE[X]+b^2E[X^2]
\end{array}$](img1.gif)
Linear Predictor
It sometimes happens that the joint probability distribution of X and Y is not completely known; or if it is known, it is such that the calculation of E[Y|X=x] is mathematically intractable. If, however, the means and variances of X and Y and the correlation of X and Y are known, then we can at least determine the best linear predictor of Y with respect to X.
To obtain the best linear predictor of Y with respect to X, we need to choose a and b so as to minimize E[(Y-(a+bX))2]. Now,
![$\begin{array}{rcl}
\displaystyle\frac{\partial}{\partial a}E[(Y-a-bX)^2]&=&-2E[...
...ial}{\partial b}E[(Y-a-bX)^2]&=&
-2E[XY]+2aE[X]+2bE[X^2]\qquad(5.3)
\end{array}$](img2.gif)
![$\begin{array}{rcl}
a&=&\displaystyle\frac{E[XY]-E[X]E[Y]}{E[X^2]-(E[X])^2}=\fra...
...[X]=E[Y]-\displaystyle\frac{\rho\sigma_yE[X]}{\sigma_x}\qquad (5.4)
\end{array}$](img3.gif)
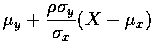 where
where
The mean square error of this predictor is given by